I have been engaged by Strategy Companion to conduct an open and unbiased exploration of their reporting solution - Analyzer, which is mainly targeted to facilitate reporting from cubes built using SQL Server Analysis Services. Also they have generously provided me an opportunity to share a few BI recipes, which I have experimented with using Analyzer. I started exploring Analyzer, and the first thing that I observed about Analyzer is that it's designed for business users, giving them the same or even more weight than technical users. Self-service BI
Self-service BI is a buzzword and sales folks generally use it as one of their Unique Selling Propositions (USPs) to market their solutions. In my view there is a difference between self-service BI and managed self-service BI. Easy authoring and controlled utilization are two of the very important factors for a self-service BI solution. If the authoring environment is not easily adaptable, there is a great chance that your solution would not get utilized at all. If utilization is not controlled there would be an explosive and unorganized utilization, as the report users would treat the reporting solution as a lab to experiment with reports in a free-flow manner. In simple language, considering a reporting solution like Analyzer, the report authoring environment should be easy enough such that business users can create their dashboards with ease. Also user and role based security should be available, so that report authoring and utilization can be managed. In this article, I intend to share the report authoring experience.
Before one makes a decision about using a product, any CEO / CIO / SVP / Analyst would want to check out certain fundamental level details about the product, which generally falls into two categories: Capital Expenditure (CAPEX) and Operational Expenditure (OPEX). Let's glide through such details in brief.
Licensing (CAPEX): Analyzer comes in different licensing flavors, and the major classifications are:Enterprise - This is for internal corporate BI applications.
OEM - Use this edition if you intend to integrate Analyzer into your own application by using the features of this solution as a web service.
SaaS - In cases where you intend to exploit the benefits of offering a reporting solution on your own cloud based platform, give a try to this edition.This version is used by companies who are hosting BI in their own cloud and (usually) charging their customers for access to a set of pre-built reports and dashboards and the data they contain, along with the ability to interact with that data.
Deployment (OPEX): Analyzer is a zero-footprint installation. This is generally a confused term with many professionals, so I would elaborate on this a bit. Analyzer can be installed on a central BI / DB server which has IIS installed on it. Or the IIS machine can be a separate machine from the BI / DB server. Analyzer needs to be installed on an IIS server (one or more) as this solution is developed using .NET and DHTML, and it also needs access to a SQL Server 2005 / 2008 / R2 database engine as it creates a database to use for its internal functioning such as metadata storage. Workstations can connect to Analyzer using just a browser which means that you do not need to install anything on client machines except a browser. This is true no matter what role the user has, such as Admin, Report Designer, or End User.
Now let's focus on the beginner level recipe to create a dashboard using Analyzer. I call this recipe as "Zero to Dashboard in 60 Minutes".
Scenario: A Sales head of a company needs to create a quick last minute dashboard to present at the quarterly board meeting. Company has a cube that is created using SSAS, and for the sake of this demo we would be using the cube created using AdventureWorks SSAS project that ships with SQL Server.
Hardware Setup: Most companies have contracts with hardware maintenance vendors, and in such environment end-user terminals are equipped with only the necessary amount of hardware required as contracts can be pay-per-use. I intentionally used a machine with 1 GB RAM, 60 GB free hard disk space, and 1.77 GHz Intel processor. This is a typical configuration of any low end laptop that should be sufficient to folks who just need to use MS Office and Outlook on their machines.
Requirements: The target audience of the dashboard is the senior management of an organization, and the Sales Head is authoring the report. Such dashboard / report can be expected to contain a few of the commonly used constituents of a dashboard.
1) A ScoreCard containing KPIs, which can be hosted in the cube
2) Strategy Map showing at least some basic kind of process flow
3) Geospatial Reporting, which is one of the best presentation forms for a senior level business audience
4) Matrix Reporting, for a detailed level study of aggregated figures
5) Filters, which are necessary to analyze the details in isolated scopes
6) Drill-Down functionality, as problems decomposition and study is carried out in a hierarchical manner.
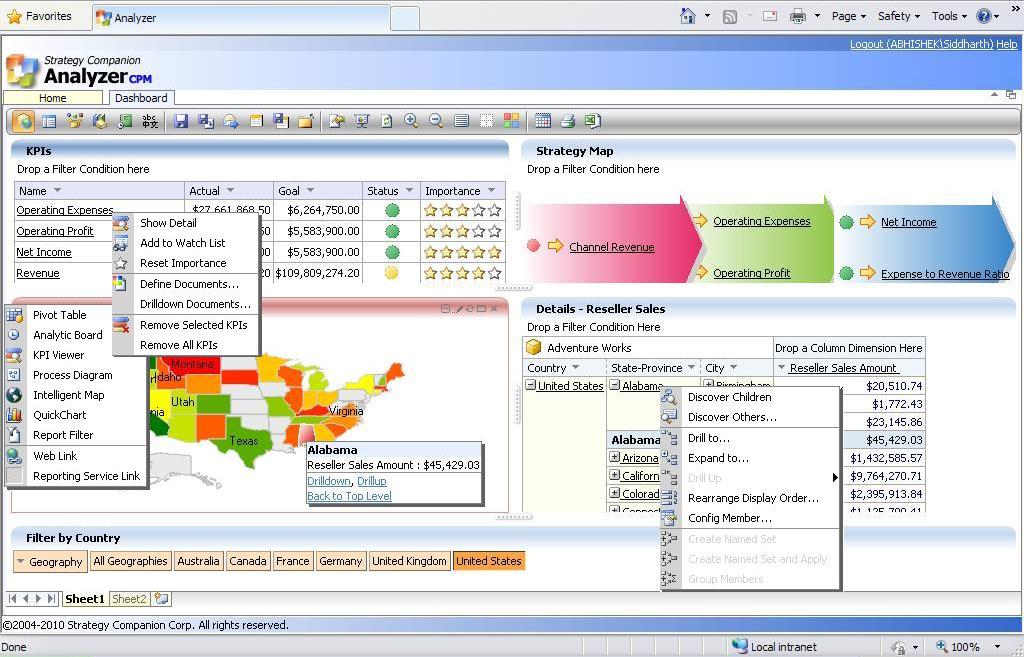
Report Authoring: I had Analyzer and the AdventureWorks cube on the same machine. Once you start Analyzer and create a new report, you would find the interface as visible in the below screenshot. To author the report, entire functionality is available on the toolbar or from context-sensitive menus. Plotting data on controls is a matter of drag-and-drop from the data tab visible on the left side.

For all the points described above in the requirements section, out-of-box controls are available.
1) KPI Viewer - This control be used for creating a scorecard hosting KPIs. Also you would find some very interesting columns like "Importance" out-of-box which can be quite an effort to create in PerformancePoint Services.
2) Process Diagram - This control can be used to create a basic level strategy map. Though this strategy map is not as appealing as a Strategy Map created out of a data-driven diagram in Visio, but still its fine enough for a last minute dashboard. Also it can host my KPIs there too.
3) Intelligent Map - This can be considered synonymous to what Bing Maps control is to SSRS. It's completely configurable and contains wide variety of maps ranging from World Map to area-specific maps.
4) Pivot Table - This control is perfectly suitable for OLAP reporting in a grid based UI.
5) Filters - Report filter have a very different UI, than traditional UI of a drop-down. Though it occupies more real-estate of screen space, it makes the report more appealing, so it's worth it. Considering the present scope of this report, I chose to place the filters at the bottom of the page, instead of placing it at the top.
You can see at the bottom of these screenshots that each report or dashboard in Analyzer can contain multiple sheets (no limit) each of which can contain its own combination of controls such as pivot tables, maps, charts, etc. In this example we are only using one sheet.
 Check out the context menus of all these different controls, and you can see what different options are available with each control. On selecting "Discover Children" at "Alabama" level in pivot table, a different sheet opens up with this wonderful report and UI, as shown in the below screenshot.
Check out the context menus of all these different controls, and you can see what different options are available with each control. On selecting "Discover Children" at "Alabama" level in pivot table, a different sheet opens up with this wonderful report and UI, as shown in the below screenshot.

Summary: With out-of-the-box controls, drag-and-drop functionality, a very decent looking report can be created in less than 60 minutes, to target the senior most audience of an organization who expect a report that supports decision making with its analytical capabilities. Provided your cube is ready with all the data structures like KPIs, Named Sets, Hierarchies, Measures, etc., reporting is almost taken care of if Analyzer is available at your disposal. A phrase that suits the summary is "Keep your ducks in a row" i.e. have your cube in proper shape to support your reporting, and then using Analyzer, below is the result that I was able to achieve in less than an hour, with very little experience using Analyzer beforehand. A more experienced Analyzer user could no doubt build this kind of report even faster.