



Elasticsearch use the Apache Lucene engine for almost all of its operations. One of the primary differences between relational databases and NoSQL systems is the way it stores data. When it comes to the storage architecture of elasticsearch, there are two terms which are key to the storage mechanism - Analysis process and Inverted Indexes.
What is Analysis process in elasticsearch ?
In Part 1, I already explained what's a tokenizer and filter in elasticsearch. Whenever an index is created, a default mapping and analyzer would be attached to it. Depending on the config of the analyzer, a tokenizer and filter would be configured for the same.
When a document request for indexing is received by elasticsearch, which in turn is handled by lucene, it converts the document in a stream of tokens. After tokens are generated, the same gets filtered by the configured filter. This entire process is called the analysis process, and is applied on every document that gets indexed.
Below is an example of the analysis process. Consider an html tag with embedded sentence as the document as the input. When the same passes through a set of filters and tokenizers, it gets converted into a set of tokens, which finally gets indexed.

What is the storage data structure of elasticsearch ? Inverted Indexes
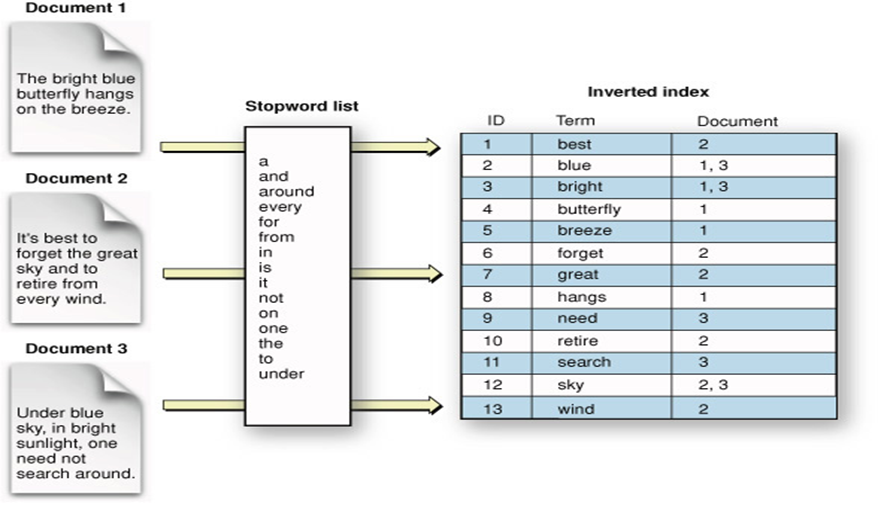
In SQL Server, we have a binary tree as the data structure for an index, for example. Post the analysis process, when the data is converted into tokens, these tokens are stored into an internal structure called inverted index. This structure maps each unique term in an index to a document. This data structure allows for faster data search and text analytics. All the attributes like term count, term position and other such attributes are associated with the term. Below is a sample visualization of how an inverted index may look like.
Post the tokens are mapped, document is stored on the disk. One can choose to store the original input of the document along with the analyzed document. The original input gets stored in a system field names "_source". Once can even choose to not analyze the input, and store the document without any analysis. The structure of the inverted index totally depends upon the analyzer chosen for indexing.
Summary: One thing to learn from this is that the key to an efficient storage and retrieval process is the analysis process defined on the index, as per the application needs.





1 comment:
Great work! Precise and acute. Thanks
Post a Comment