Data representation has many forms. The intended method and purpose of analysis as well as the nature of the data will determine which form of data representation is most appropriate. With the growing need for better analytics, reports today are increasingly expected to be interactive enough to facilitate analysis.
When it comes to geospatial reporting, the first challenge is to associate two entities together – Data and Geography. Geography is usually represented on a map, and associating data to a map requires a geographical element in your data to associate the two entities with each other. Reporting geospatial data is not something new, but reporting it intelligently requires some reasonable effort, and in this Analyzer recipe, we would take a look at what is the difference between reporting geospatial data and reporting the same in an intelligent manner.
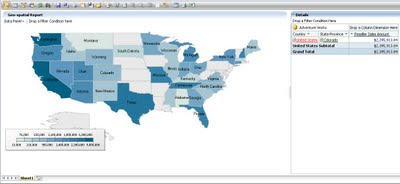
Analyzer has two fundamental reporting controls related to this discussion – Intelligent Map and Pivot Table. To create a geospatial report, I used the “Reseller Sales Amount” measure as the data, the “Geography” hierarchy of the Geography dimension from the AdventureWorks cube, and added the same to the Intelligent Map control. Side-by-side I added a Pivot Table control and added the same entities to it. Effortlessly I created a geospatial report with a lot of built-in features provided out-of-box. The Intelligent Map control consists of a reasonable number of different maps including the world map, which I have used in my report. Many additional maps are available free of charge on the Internet. Strategy Companion has a list of some of the web sites where you can find these maps, which use the Shapefile format (.shp extension) created by ESRI, a well-known GIS company.

The first question that may come to mind is why is the pivot table added to the report, when a map is already there? The Intelligent Map control actually is quite intelligent as we will see through the course of our demo. The first point of intelligence is that, just from the Geography hierarchy, this control has associated all the locations correctly on the map. When you would hover over a particular area, you can see the associated data value in the tool tip. The feature that makes me happy is that it provides an out-of-box drill-down feature. The reason for having the pivot table is that if the user intends to figure out the point of analysis, all information would be required at a glance and the user cannot be expected to hover everywhere. So the pivot table acts as the data coordinates for the geospatial representation of the report.
To take this to the next level, double-click the report to drill down to the next level in the hierarchy of the selected area. The difference in color shows the performance of the area and the same can be measured from the scale shown on the report. Analysts would generally use the very intuitive and visual approach of figuring out the area of interest based on the varying shades of colors (you can also choose to use several different colors such as red, yellow, and green) and then get into the numeric details. The pivot table is also capable of drilling into the data and you can get all the details from there. You may also choose to expose one region’s details on the map while simultaneously showing the details for another region on the pivot table.
 Pivot tables (also commonly called grids) are generally used for slicing and dicing of data, and geospatial representation of the data is used for distribution analysis of data over a selected geography. One problem from the above report is that you would not find names represented on some areas, also some areas might be very small from a geography perspective. In the pivot table you would find a long list for State-Province under United States. So how do you associate these two? The answer is “Manually”, as there is no association between these two parts of the report. Ideally after drilling down the geography, data distribution has become large, so geospatial representation is convenient for users to select area to start slicing-dicing. But this needs both types of the report components to work in harmony.
Pivot tables (also commonly called grids) are generally used for slicing and dicing of data, and geospatial representation of the data is used for distribution analysis of data over a selected geography. One problem from the above report is that you would not find names represented on some areas, also some areas might be very small from a geography perspective. In the pivot table you would find a long list for State-Province under United States. So how do you associate these two? The answer is “Manually”, as there is no association between these two parts of the report. Ideally after drilling down the geography, data distribution has become large, so geospatial representation is convenient for users to select area to start slicing-dicing. But this needs both types of the report components to work in harmony.
With this comes the challenge of usability, interactivity and intelligence all at the same time. The Intelligent Map control is capable of addressing these challenges. In the below screenshot you can see that this control can be set to support slicing-and-dicing data as the primary objective. Also the scope of actions on this control can be specified, which gives the flexibility to associate the actions performed on this control on different parts of the report.
 After configuring this control, check out the report. Drill down on “United States”, and you would find that not only the map has gotten drilled down to the lower level, but the pivot table also works in harmony with the selected geography. I selected “Colorado” and on the grid the same got selected readily. Users do not need to scroll long lists to locate the area which they selected on the map for analysis. With an interactive Intelligent Map and Pivot Table, both capable of drill-down and drill-through features, and capable of working in harmony, users almost have a gadget in the form of a report, to perform slicing-and-dicing driven by geospatial analysis.
After configuring this control, check out the report. Drill down on “United States”, and you would find that not only the map has gotten drilled down to the lower level, but the pivot table also works in harmony with the selected geography. I selected “Colorado” and on the grid the same got selected readily. Users do not need to scroll long lists to locate the area which they selected on the map for analysis. With an interactive Intelligent Map and Pivot Table, both capable of drill-down and drill-through features, and capable of working in harmony, users almost have a gadget in the form of a report, to perform slicing-and-dicing driven by geospatial analysis.
From a Microsoft BI products perspective, the ingredients I would need to create this geo-spatial recipe are: SSRS Bing Maps control, Grids (SSRS Tablix / PPS Analytical Grid) with drill-down and drill through enabled and connected using Sharepoint webparts. And still making them work in the same harmony as shown above would not be as effortless as this. Of course, each platform has its own advantages and limitations. To explore what more Analyzer has to offer compared with other reporting tools, you can download an evaluation version of Analyzer from here.